
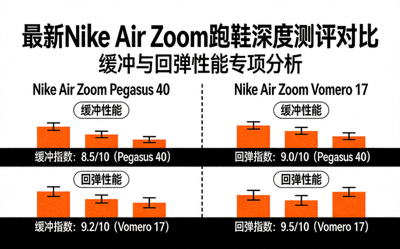
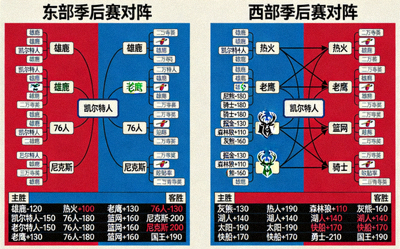


足球数据分析革命:如何利用机器学习预测比赛结果与球员表现
在现代足球领域,数据分析已从简单的统计迈入了机器学习与人工智能的深度应用阶段。传统的数据指标如射门次数、控球率、传球成功率,虽然能反映比赛概况,但往往无法精准预测结果。近年来,越来越多的俱乐部与数据分析公司开始构建复杂的预测模型。
模型构建的核心变量
这些模型通常纳入数百个变量,包括但不限于:球员的实时生理数据(通过穿戴设备收集的心率、疲劳度)、历史对阵战绩(考虑主场优势、天气条件)、球队战术风格匹配度(例如高位压迫球队对阵低位防守球队的预期效果)、甚至社交媒体上球迷的情绪指数。通过监督学习算法,模型能够从海量历史比赛中学习,找出胜平负结果与这些变量之间的非线性关系。
在球员表现预测中的应用
除了比赛结果,机器学习模型也被用于预测个体球员的表现。例如,通过分析一名前锋过去100场比赛的射门位置、防守球员距离、触球次数等数据,可以预测他在下一场特定对手面前的预期进球数(xG)。这对于球队的战术布置、转会市场估值以及博彩行业的赔率设定都产生了深远影响。一些英超俱乐部甚至利用此类模型来决定是否让某位球员首发,或者评估其伤病恢复后的状态风险。
面临的挑战与未来
然而,足球预测模型也面临“黑天鹅事件”的挑战——突如其来的红牌、关键球员的意外伤病、裁判的争议判罚,这些难以量化的因素仍然会干扰预测准确性。未来的方向可能是融合更多实时数据流(如现场摄像头追踪的球员微表情、教练的即时指令),并采用更先进的神经网络模型,以提高预测的鲁棒性。无论如何,数据驱动的决策正在深刻改变足球世界的游戏规则。
阅读完整深度分析